Можно ли сэкономить набирая junior специалистов?

Дисклеймер №1: По стопам предыдущих двух статей «Эффективность по Skunk Works» и «У нас нет ресурсов для ревью кода»
Дисклеймер №2: Безусловно разделение на junior-middle-senior,
Дисклеймер №1: По стопам предыдущих двух статей «Эффективность по Skunk Works» и «У нас нет ресурсов для ревью кода»
Дисклеймер №2: Безусловно разделение на junior-middle-senior,
Прочитал «Skunk Works. Личные мемуары моей работы в Локхид»
Очень занятная книга об одном из самых секретных КБ времен холодной войны по ту сторону океана. Много
Если бы меня сейчас спросили, какой самый важный процесс в компании, то ответил бы: работающий процесс. Но работающий процесс это курица или яйцо? Тогда мой
В какой то момент осознаешь, что список когнитивный искажений знать полезнее, чем список шаблонов проектирования или умение забивать гвозди.
Последнее время часто слышу «у нас нет ресурсов на ревью кода» или «Нет времени вводить ревью сейчас, у нас много багов, надо их править. Вот
Честно подсмотрено.
THeader = record
x,y,z: TMyRecordField;
NextLabel: packed record end;
end;
На сколько прекрасно, на столько и отвратительно. Но восхищает однозначно хотя бы тем, что это вообще
Данная заметка — реакция на статью http://alexnesterov.com/code-review/, где практика code review рассматривается как антипаттерн, а парное программирование как способ решить задачи ревью кода правильно. Конечно же, у парного программирования
Вот код примера:
program ReferenceToProc;
{$APPTYPE CONSOLE}
{$R *.res}
uses
System.SysUtils, System.Generics.Collections;
var
eventHandlers: TList<TProc>;
procedure Subscribe(AHandler: TProc);
begin
eventHandlers.Add(AHandler);
end;
function Unsubscribe(AHandler: TProc): Boolean;
begin
Writeln(eventHandlers.IndexOf(AHandler)); // 0
Result := eventHandlers.Remove(AHandler) >= 0;
end;
procedure HandlerProc;
begin
Writeln('Вызов статической процедуры');
end;
var
proc: TProc;
begin
eventHandlers:= TList<TProc>.Create;
proc := procedure()
begin
Writeln('Вызов анонимной функции')
end;
Subscribe(proc); // Подписываемся анонимной функцией
Writeln(Unsubscribe(proc)); // Метод вернул True, Успех:)
Subscribe(HandlerProc); // Подписываемся не анонимной функцией
Writeln(Unsubscribe(HandlerProc)); // Метод вернет False Fail:(
FreeAndNil(eventHandlers);
readln;
end.Вызов Unsubscribe в строке Writeln(Unsubscribe(HandlerProc)); вернет False. Причина впрочем прозаична, вызов метода HandlerProc заворачивается в анонимную функцию и каждый раз новую. Потому функция, которую подписали на событие, будет отличаться от функции, которую пытаемся отписать.
Казалось бы, простая задача — реализовать список с обработчиками и методами подписки и отписки превращается не в самую тривиальную.
Получается, что хранить обработчики лучше как TMethod, но если все же хотим уметь подписывать универсальные обработчики (анонимные и неанонимные), тогда придется для каждого типа писать свою логику сохранения в список и вызова обработчиков. Это будут либо overload методы, либо будем использовать Rtti и методы параметризированные типом.
TEvent = class
events: TList<TMethod>;
class procedure Subscribe(AProc: TProc); overload;
class procedure Subscribe(AProc: TProcedure); overload;
class procedure Subscribe<T>(AProc: T); overload;
end;А для преобразования анонимного метода в TMethod потребуется сочинять что то вроде того, что написано в Spring4D в Springs.Events.pas:
procedure MethodReferenceToMethodPointer(const AMethodReference; const AMethodPointer);
type
TVtable = array[0..3] of Pointer;
PVtable = ^TVtable;
PPVtable = ^PVtable;
begin
// 3 is offset of Invoke, after QI, AddRef, Release
PMethod(@AMethodPointer).Code := PPVtable(AMethodReference)^^[3];
PMethod(@AMethodPointer).Data := Pointer(AMethodReference);
end;
function TEvent.Cast(const handler): TMethod;
begin
if fTypeInfo.Kind = tkInterface then
MethodReferenceToMethodPointer(handler, Result)
else
Result := PMethod(@handler)^;
end;
MyObject.OnEvent := procedure()
begin
MyObject.OnEvent := nil;
MyField.MyProp := 'Value';
end;
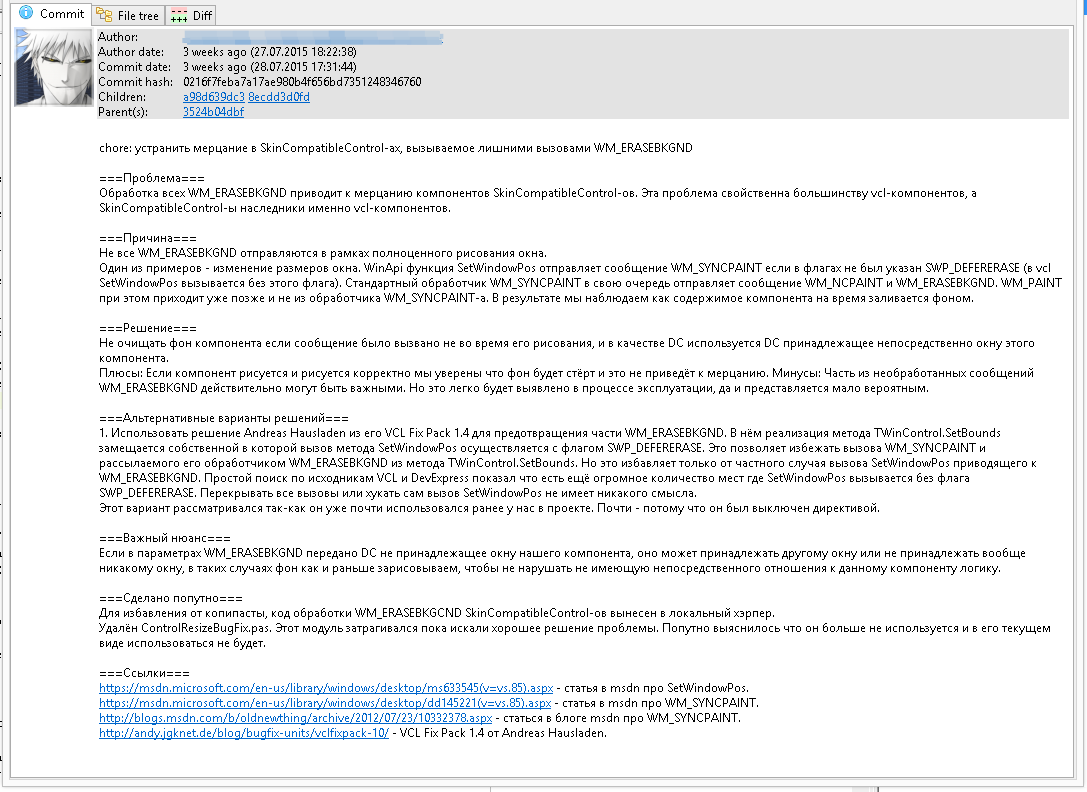
| 1. | На первом шаге у нас была одна постоянная ветка, бранчи использовались очень эпизодически и не было стабильной версии продукта. Да и так бывает. Бывало даже так, что одним коммитом фиксировалось сразу несколько задач. С этого мы начинали. | ||
| 2. | Потом появились ветки SVN (до SVN использовали VSS и Perforce). SVN — хорошая система. Какое-то время использовали собственную модель бранчевания, потом сдались и перешли на стандартную раскладку trunk, tags, branches. В branches мы создавали ветки только под большие задачи. Прошло много времени, но я хорошо помню боль и отчаянье от работы с ветками в SVN. Это было долго — долго создавать ветки, долго переключать, долго смотреть лог, а слияния веток превращались в испытание. Но с проблемами можно было мириться, если работать только с долго живущими ветками. | ||
| 3. | А следом появилось ревью кода. Это была практика, которая все перевернула. Сейчас мне сложно представить разработку без ревью. | ||
| 4. | Идеальным дополнением к ревью кода стал Git. Модель Git (DVCS) как нельзя лучше подходит для ревью кода. Следующие пункты раскроют это утверждение. | ||
| 5. |
Первым делом мы ввели правила написания текста коммита. Как писать коммит у нас жестко формализовано. Сами правила начали появляться еще при SVN, но только переход на Git заставил к ним относиться строго. Главное требование гласит: текст коммита обязан содержать мотивацию принятия решений и изменений, присутствующих в коде коммита. Перед выкладыванием на сервер каждая задача проходит ревью кода. Ревью кода выполняется с помощью инструмента CodeReviewer. И вот тут основной момент — ревьюверу задачи должно быть понятно все только на основе информации из коммита: непосредственно кода и текста описания коммита. Если возникают вопросы, то описание коммита перерабатывается. Можно найти множество плюсов подобного подхода:
Раньше типичные коммиты были вот такими:
Полный зоопарк стилей и практически полное отсутствие информативности. Чтобы понять, что же сделано в коммите, необходимо смотреть код и собирать по крупицам информацию из разных источников. Разработчики, которые заползали в такой код, могли многократно ходить по одним и тем же граблям. А про автора думать самые нелицеприятные вещи, задаваясь вопросом под какими запрещенными веществами код был написан. Ирония заключается в том, что нередко рассерженный разработчик является автором злосчастного коммита. Теперь текст коммита стал вот таким:
При этом мы придерживаемся правила — код должен документировать сам себя. Комментарий в коде — признак плохого кода. Цель описания в коммите — не описание изменений, а описание почему именно так, а не иначе. В тексте коммита можно описать альтернативные варианты решения с плюсами и минусами. К слову сказать, текст коммита у нас так же ревьювируется как и код. В SVN это правило было тяжело соблюдать. Как правило, задача уходила на сервер одним коммитом, что бы не получить в централизованном репозитории не консистентного состояния. Описание всех изменений в одном коммите теряет свою красоту и эффективность. В git’е каждую задачу можно декомпозировать до небольших логических шагов, о чем в следующем правиле. |
||
| 6. |
Правила оформления задачи в ветках.
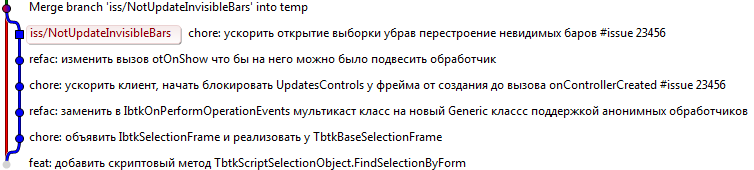
Каждую задачу, как правило, можно декомпозировать на несколько шагов. Отделив, например, рефакторинг от непосредственно кода, исправляющего ошибку. Каждый шаг — отдельный коммит в отдельной ветке задачи. В последствии вся ветка попадет в центральный репозиторий, сохраняя для поколений структурированное решение задачи. Теперь даже коммит, который был выполнен «заодно» и не являющийся непосредственно необходимым для закрытия задачи, находится в контексте задачи (в той же ветке), позволяя видеть цель и мотивацию автора.
Задача в SVN — это большой, размазанный по разным модулям патч. Больших усилий стоит разобраться в таком патче. Гораздо проще, когда каждая задача — это структурное решение, и можно пробежаться по отдельным шагам. В таком решении отделяются «зерна от плевел».
Репозиторий стал неотъемлемой частью кода проекта.
Пример:
По ходу ревью в код могут вносится изменения, каждое такое изменение может вносится squash коммитом. Это коммит, который в последствие с помощью команды rebase можно объединить с другим коммитом (что бы ощутить мощь Git достаточно пробежаться по оглавлению способов изменить историю https://git-scm.com/book/ru/ и http://97things.oreilly.com/wiki/index.php/Record_your_rationale). |
||
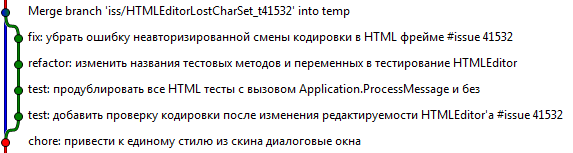
| 7. | Правило «юнит тесты до функциональности». Это правило говорит о том, что юнит тесты должны располагаться в дереве коммитов до исправления ошибки, которую они тестируют. В результате всегда можно проверить работу юнит теста до исправления ошибки и после. Убедиться, что тест и исправление написаны верно.
Пример:
|
«В первые годы работы над ракетной техникой практически никто из руководителей, критикующих завод, не мог конкретно сформулировать, что нужно сделать для повышения культуры производства, определить роль каждого начальника цеха, мастера и рабочего. Было слишком много общих решений. Устинов беспощадно расправлялся с начальниками цехов и производств за грязь и бескультурье. При посещениях завода он начинал с туалетов. Обычно в цехах задолго до подхода к туалету разносился характерный «аромат». В самих туалетах надо было ходить по лужам. Устинов приходил в ярость и гремел: «Какой сортир, такой и начальник цеха. Пока не добьетесь образцовой чистоты в своих сортирах, не будет чистоты и в цехах».С тех пор прошло очень много лет. Проблема чистоты общественных туалетов на наших заводах и в институтах так же, впрочем, как и в стране в целом, не решена. Это оказалось куда труднее, чем создать самое грозное ракетно-ядерное оружие и завоевать мировой приоритет в космонавтике.Явный дефицит культуры, общей производственной чистоты и гигиены до сих пор является одной из причин низкого качества многих отечественных изделий. За время войны и в последующие годы забота об элементарном комфорте в цехах, создание рабочему достойной и привлекательной общей обстановки считались излишней и непозволительной роскошью. Затраты на чистоту, комфорт, элементарный сервис с лихвой окупаются повышением производительности и качества. «